理解编码
编码
- 编码种类
编码的种类有多种,如- ascii
- gbk
- utf-8
- …
- 编码实质
编码的实质是一张人与计算机之间信息的对照表,如下ascii这种编码,部分内容如下图
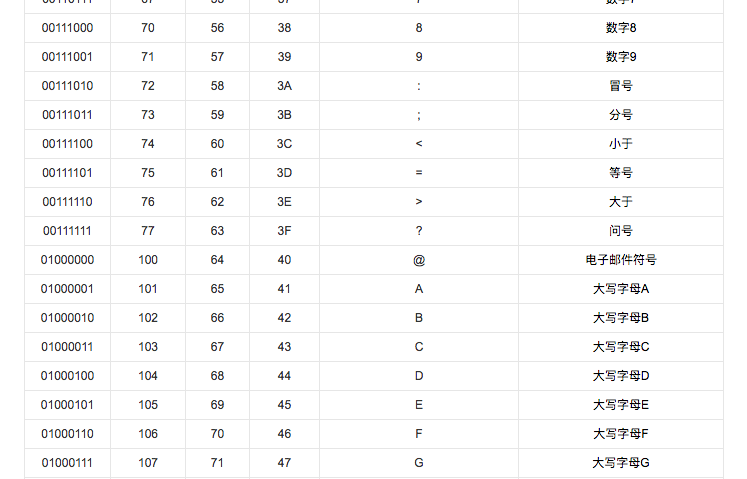
- 为什么需要编码
人只认识字符串,如”你好”,”hello”这样的形式的信息.计算机只”认识”二进制内容,如”001010101010101”这样的信息- 人与人之间:通过字符串交流
- 计算机与计算机之间:通过二进制交流
- 人与计算机之间:通过翻译来交流
编码(这张人与计算机之间信息的对照表)就是这个翻译,编码就是翻译,编码就是翻译
<img src=”“hello”.encode(“ascii”)” data-action=”zoom”>
理解编码
人与计算机交流
计算机在本地存储和通过网络发送的都是二进制的数据(0101010串),人要将信息存储在计算机则需要将人想存的”字符串”通过编辑软件如notepad.exe进行编码后进行存储,notepad.exe等编辑工具会自动进行编码,人也可告诉notepad.exe用什么编码种类(如ascii,gbk)进行编码.人若想读取计算机存储好的内容(二进制数据),需要通过编辑软件如notepad.exe进行解码成”字符串”,人才能读懂自己原来存储的信息.
“最弱”的ascii码
ascii编码只懂得英文字符(键盘上的符号)与0101串之间的翻译,其他的编码都”具备”ascii编码这个翻译员的知识,如果英国人将英文编码成0101串后中国人通过gbk编码来翻译是可以翻译成功的,因为gbk编码这个翻译员具备ascii编码这个翻译员的知识,如下:
In Out[2]: b'hello'
In [3]: "hello".encode("ascii").decode("gbk")
Out[3]: 'hello'
In [4]: "hello".encode("ascii").decode("gbk")
Out[4]: 'hello'
编码的”专一”
ascii码和gbk码就像英国人的翻译和中国人的翻译(这里的翻译指的是人与计算机之间的交流,而不是英国人和中国人之间的交流),如果中国人通过gbk码(不能将中文通过ascii进行编码,因为ascii编码这个翻译员不知道中文该怎么翻译)将他们的信息进行编码后通过计算机发送给英国人,英国人想通过ascii码将这个信息解码,结果会失败,因为ascii码这个翻译人员的能力有限,ascii码这个翻译员只懂得英文和0101,英国人尝试通过ascii码这个翻译员来将计算机发来的信息(这个信息是通过gbk码翻译员翻译成0101的结果)翻译成英文时,由于ascii码这个翻译员的脑子里不知道看到的0101串对应的是什么英文,于是翻译不来,如下:
In [5]: "你好".encode('ascii')
---------------------------------------------------------------------------
UnicodeEncodeError Traceback (most recent call last)
<ipython-input-5-f2b92576099c> in <module>()
----> 1 "你好".encode('ascii')
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
“特殊”的utf-8编码
utf-8编码这个翻译员能力比较强大,能将中文,日文和其他语言都翻译成0101串,如下:
In [7]: "你好".encode("utf-8")
Out[7]: b'\xe4\xbd\xa0\xe5\xa5\xbd'
In [8]: "こんにちは".encode("utf-8")
Out[8]: b'\xe3\x81\x93\xe3\x82\x93\xe3\x81\xab\xe3\x81\xa1\xe3\x81\xaf'
In [9]: "你好".encode("utf-8").decode("utf-8")
Out[9]: '你好'
In [10]: "こんにちは".encode("utf-8").decode("utf-8")
Out[10]: 'こんにちは'
不过,虽然utf-8编码这个翻译员能力比较强,但是如果想把gbk编码的内容通过utf-8来解码,是不行的,因为gbk编码和utf-8编码是两种不同的编码,也即两个不同的翻译员(这两个翻译员能力不同),这两个翻译员除了对英文的知识的掌握是相同的以外,其他各自具备的知识是不同的,utf-8编码这个翻译员只懂得将utf-8自己编码过的内容解码,gbk翻译员也只懂得将gbk自己编码过的内容解码,如下:
In [11]: "你好".encode("gbk").decode("utf-8")
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-11-161972ecc108> in <module>()
----> 1 "你好".encode("gbk").decode("utf-8")
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc4 in position 0: invalid continuation byte
In [12]: "你好".encode("utf-8").decode("gbk")
Out[12]: '浣犲ソ'