学习urllib2+BeautifulSoup:爬乌云所有厂商url列表
3 minute read
0x01 需要注意的事项:
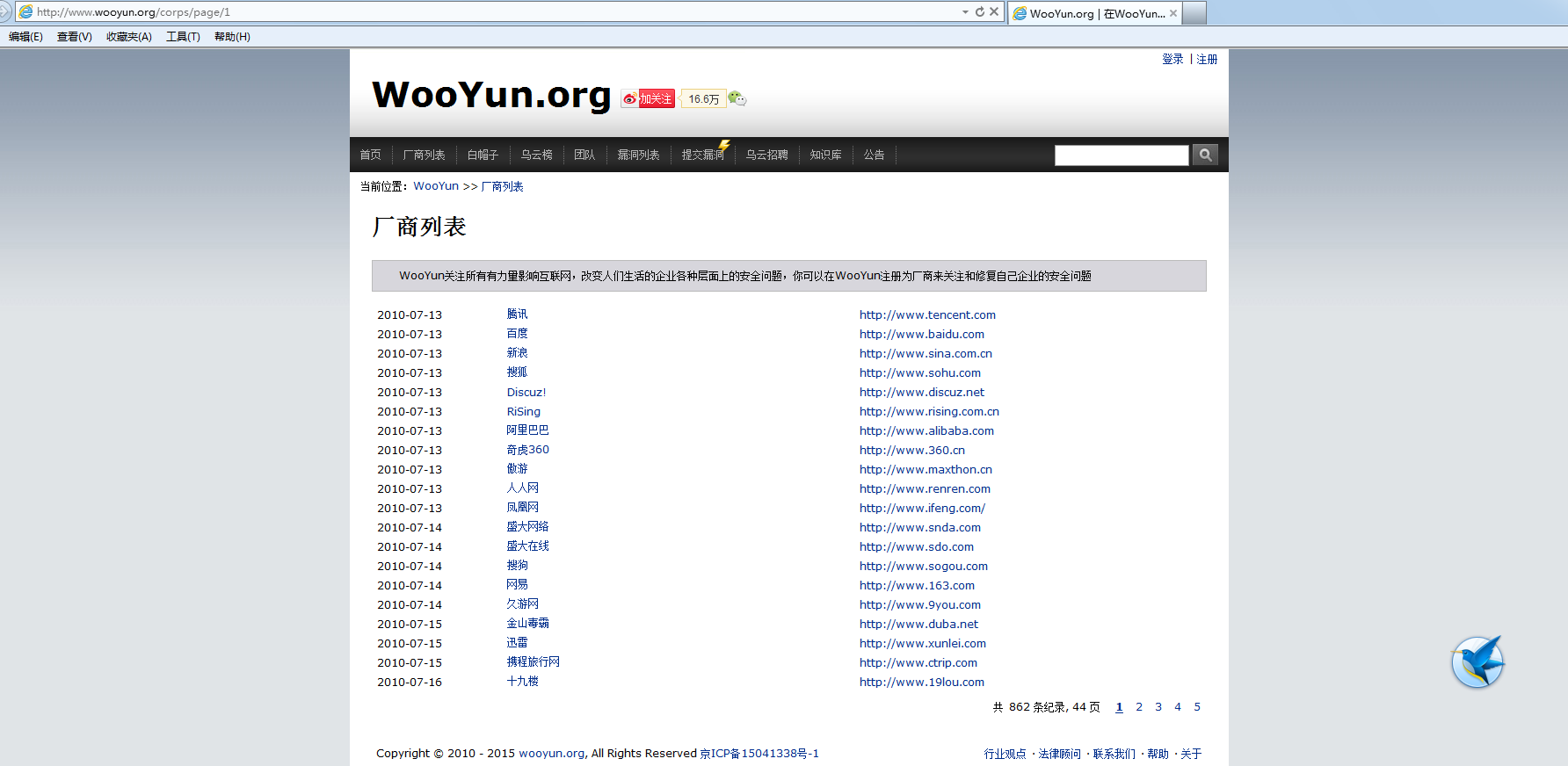
1>Wooyun访问时不能有vpn,否则爬不到厂商列表.
https://www.wooyun.org/corps/page/1
(in vpn)
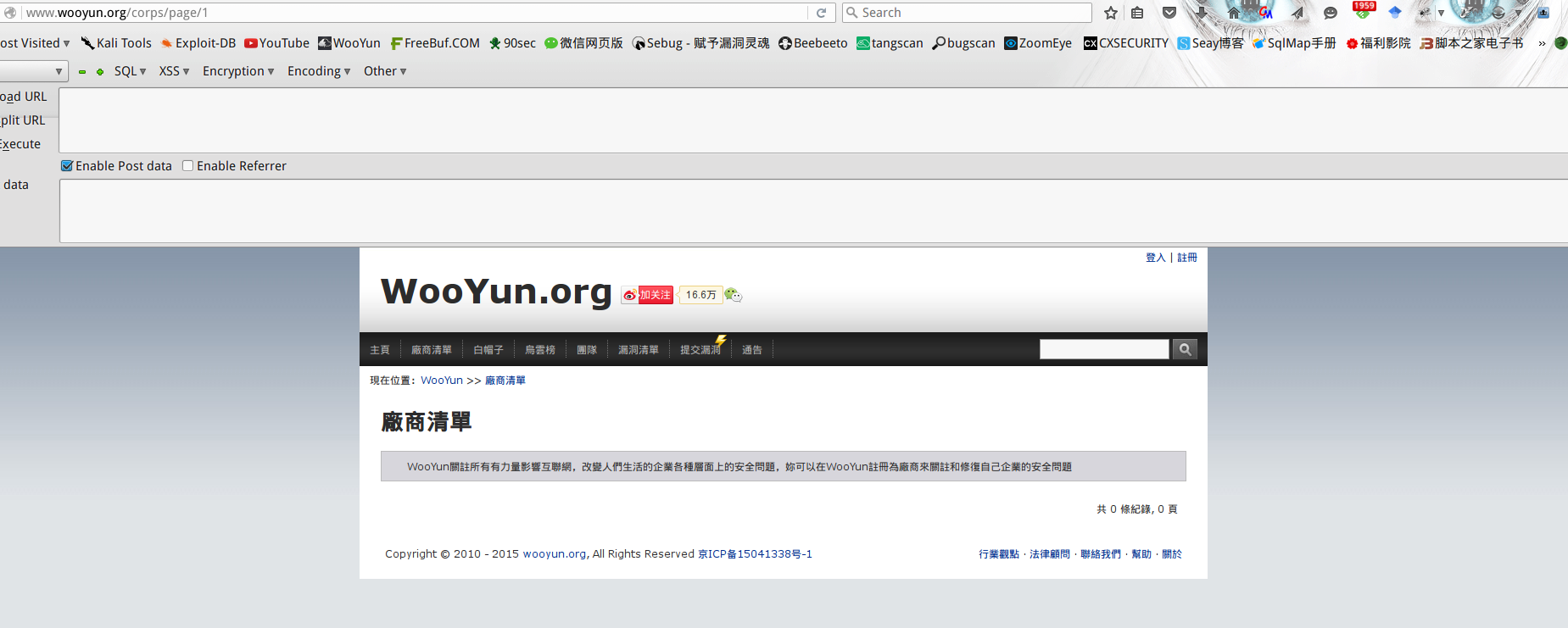
(not in vpn)
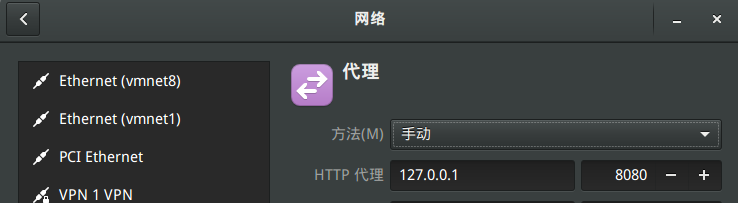
2>chrome的代理设置问题
系统安装了google的chrome浏览器,需要burp截chrome的包时会在里面设置代理,而chrome设置的代理即是系统的代理,而firefox设置的代理只是firefox浏览器的代理,并不影响系统的网络访问是否要经过firefox设置的代理,如果设置了chrome的代理如127.0.0.1:8080,事后忘记关闭,则会影响到系统中所有需要联网的程序.
3>urllib2 默认会使用环境变量 https_proxy来设置 HTTP
如果想在程序中明确控制 Proxy 而不受环境变量的影响,可以使用自己设置的代理,可以设置代理为空:
null_proxy_handler=urllib2.ProxyHandler({})
opener=urllib2.build_opener(null_proxy_handler)
urllib2.install_opener(opener)
这样就不会出现urllib2 error 101 refused的错误了,也可以将系统的127.0.0.1:8080的代理关掉.(linux中set命令可以看到https_proxy的值,https_proxy并不是vpn的ip)


4>sublimeREPL插件
在sublime text中有个sublimeREPL插件,f5快捷键可编译运行python脚本,然而就算系统设置了代理127.0.0.1:8080等,f5依然可以将使用了urllib2且没有加上面3行代码的python脚本成功执行,也许是sublimeREPL中默认的运行代码设置了自己的代理为空,且不影响系统代理https_proxy的值.
0x02 最后代码如下:
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
#必须加上上面四行,否则各种编码的错误爆出
from bs4 import BeautifulSoup
import re
import urllib2
import urllib
from urlparse import *
def spider(uri):
global all_list
print uri
null_proxy_handler=urllib2.ProxyHandler({})
opener=urllib2.build_opener(null_proxy_handler)
urllib2.install_opener(opener)
req=urllib2.Request(uri)
req.add_header('user-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)')
response=urllib2.urlopen(req)
html=response.read()
soup=BeautifulSoup(html,"html.parser")
for i in soup.find_all(rel="nofollow"):
each=i.get_text()
url=urlparse(each)
url=url.scheme+"://"+url.netloc
all_list.append(url)
global temp
global num_of_all_pages
global static_uri
temp+=1
print "爬完第%d页".decode('utf-8') % temp
if temp==1:
static_uri=uri[0:-1]
all_text=soup.get_text().decode('utf-8')
p='共.*条(.*)页'.decode("utf-8")
#这里使用u'共\d{3,4}条.*(\d{2,3})页.*'无法匹配到,可能是因为pattern为u'...'时,\d匹配不到数字
se=re.search(re.compile(p),all_text)
result1=se.group()
print result1
se1=re.search(re.compile(r'\d{3,4}.*(\d{2,3})'),result1)
num_of_all_pages=int(se1.group(1))
next_ur=temp+1
next_uri=static_uri+"%s" % str(next_ur)
print 'next_uri is %s' % next_uri
print 'temp:%d' % temp
print 'num_of_all_pages:%s' % num_of_all_pages
if temp<num_of_all_pages:
spider(next_uri)
all_list=[]
temp=0
num_of_all_pages=0
static_uri=""
spider("https://www.wooyun.org/corps/page/1")
print all_list
f=open("targets.txt","a+")
for each in all_list:
f.write(each+'\n')
f.close()