深入理解计算机系统第3章笔记
程序的机器级表示
1.编译器驱动程序将源文件翻译成可执行目标文件可分为4个阶段完成

a.gcc -O1 -S hello.c中:gcc也可用cc缩写代替,-O1表示编译器优化级别,-S表示生成汇编代码,结果为hello.s[汇编]
b.gcc -O1 -c hello.c:gcc会编译并汇编,得到hello.o,hello.o是二进制格式,可用objdump -d hello.o查看汇编格式内容
c.gcc -O1 -o hello hello.o main.c:可由gcc产生可执行文件hello,可用objdump -d hello反汇编hello这个可执行文件[反汇编]
d.上面a中的汇编过程默认得到的为ATT格式的汇编代码,要得到intel格式的指令为:gcc -O1 -S -masm=intel hello.c
2.gcc生成的汇编指令都有一个字符后缀,表明操作数的大小,movb表示传送字节(eg,对应al/ah),movw表示传送字(eg,对应ax/bx), movl表示传送双字(eg,对应eax/ebx)
3.mov指令有个限制,传送指令的两个操作数不能都指向存储器位置.eg,mov [0x1000],[0x2000]是不允许的,需要mov eax,[0x1000]先,再mov [0x2000],eax
4.movs和movz都是将一个较小的数据复制到一个较大的数据位置,高位用符号位扩展(movs)或者用零位扩展(movz)进行填充
5.movsbl:将b符号扩展(s)成l格式后再mov到l,movzwl:将w零扩展(z)成l后再mov到l,eg:假设%dh=CD(1100 1101),%eax=98765432
movb %dh,%al %al=%dh=CD,%eax=987654CD
movsbl %dh,%eax sbl:%dh->FFFFCD,%eax=FFFFCD
movzbl %dh,%eax zbl:%dh->0000CD,%eax=0000CD
6.左移右移汇编指令
sal:算术左移
shl:逻辑左移
sar:算术右移
shr:逻辑右移
sal=shl,只有算术右移(sar)操作要求区分有符号和无符号操作数,shr在高位补0,sal和shl在低位补0,这个特性使得补码运算
成为实现有符号整数运算的一种比较好的方法
7.c/c++中的goto与汇编中的jmp addr等同,条件数据传送指令比条件控制转移的性能好
条件数据传送,eg:
cmp %edx,%ecx
cmovl %ebx,%eax(此处的l代表less,不是att中的movl中的long)
8.leave+ret恢复栈的状态到调用函数前
leave=mov esp,ebp+pop ebp[执行pop ebp后此时esp指向的是old_eip]
retn n==pop eip+mov esp,esp+4*n+jmp eip
(栈中大地址)
参数n
...
参数1
old_eip <--对应--> push old_eip
old_ebp <--对应--> push ebp+mov ebp
被保存的寄存器,本地变量和临时变量
(栈中小地地)
9.寄存器使用惯例
a)eax,edx,ecx被划分为调用者保存寄存器 [x86-64中变成r10和r11两个寄存器]
过程p调用q时,q可以覆盖这些寄存器,而不会破坏任何p所需要的数据
也即调用者在调用其它函数前会自行保存这些寄存器在调用者的栈桢中,调用完成后会恢复(pop)这些保存过的寄存器
b)ebx,esi,edi被划分为被调用者保存寄存器 [x86-64中变成:rbx,rbp,r12-r15]
q必须在覆盖这些寄存器的值之前,先把它们保存到栈中,并在返回前恢复
也即被调用者在返回到调用者的栈桢中前会在当前被调用者自己的栈桢中保存这些寄存器,并在返回前恢复(pop)
10.被调用的函数的参数在被调用的函数当前栈桢中的位置如下,其中ebp是被调用函数当前栈桢中的ebp,old_eip是在调用被调用 函数的调用函数中的call xxx(xxx表示被调用函数的名称)所在汇编语句的下一句汇编语句的内存地址
old_eip:ebp+0x4
第1个参数:ebp+0x8
第2个参数:ebp+0xc
第n个参数:ebp+0x4(n+1)
11.c语言允许对指针进行运算,而计算出来的值会根据该值引用的数据类型的大小进行伸缩,也就是说,如果p是一个指向类型为T的 数据的指针,p的值为\(X{i}\),那么表达式p+i的值为\(X{p}+l\ast i\),这里l是数据类型t的大小
#include <stdio.h>
int main(){
int iV=3;
void* a=&iV;
printf("a:%p",a);
void *b=a+1;
void *c=a-1;
printf("\n");
printf("b=a+1:%p",b);
printf("\n");
printf("c=a-1:%p",c);
printf("\n");
printf("b-a:%p",b-a);
return 0;
}
上面运行结果为
a:0x7fff508f85c8
b=a+1:0x7fff508f85c9
c=a-1:0x7fff508f85c7
b-a:0x1#
将其中的void *换成int *后代码如下
#include <stdio.h>
int main(){
int iV=3;
int* a=&iV;
printf("a:%p",a);
int *b=a+1;
int *c=a-1;
printf("\n");
printf("b=a+1:%p",b);
printf("\n");
printf("c=a-1:%p",c);
printf("\n");
printf("b-a:%p",b-a);
return 0;
}
运行结果变成如下
a:0x7fff506ab5c8
b=a+1:0x7fff506ab5cc
c=a-1:0x7fff506ab5c4
b-a:0x1#
12.类似于数组的实现,结构的所有组成部分都存放在存储器中一段连续的区域内,python中没有结构体,可用类来代替
class mystruct:
def __init__(self):
self.name=""
self.size=10
self.list=[]
a=mystruct()
a.name='cup'
a.size=8
a.list.append('water')
13.一个联合(union类型)的总的大小等于它最大字段的大小,联合中的每个元素的偏移都是0
14.DDD是GDB的一个扩展,提供了图形界面,据说功能强大follow
15.x86-64下寄存器比IA32的寄存器:
寄存器数量翻倍至16个,新增加的寄存器命名为%r8-%r15
可直接访问每个寄存器的低32位(%eax,%ecx,%edx...,%r8d-%r15d)
可直接访问每个寄存器的低16位(%ax,%cx,%dx...,%r8w-%r15w)
可直接访问每个寄存器的低8位

16.x86-64与栈相关的特性
a)将函数参数保存在寄存器上,不保存在栈上(参数>6个除外)
b)程序不再需要信赖栈来存储和获取过程信息,极大地减少了过程调用和返回的开销
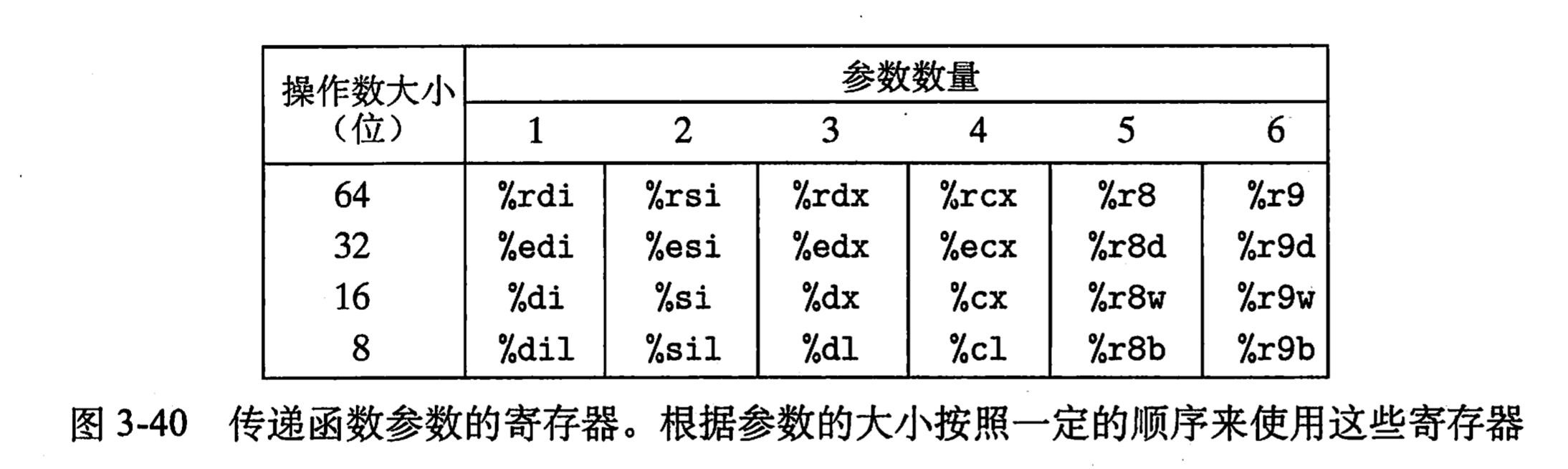
c)最多可以有6个整型(整数和指针)参数可以通过寄存器进行传递,寄存器名对应于所传递的数据的大小,如下图
d)在调用过程中,栈指针保存在固定的位置(rsp),使得可以用相对于栈指针的偏移量来访问数据,因此不再需要栈底指针(ebp)
e)函数过程的栈帧通常有固定的大小,在过程开始时通过减小栈指针(rsp)来设置(如某函数的开始就是subq $32,%rsp)
f)使得函数可能需要栈帧的原因如下:
1)局部变量大多,不能都放在寄存器中
2)有些局部变量是数组或是结构
3)函数用取地址操作符(&)来计算一个局部变量的地址
4)函数必须将栈上的某些参数传递到另一个函数
5)在修改一个被调用者保存的寄存器前,函数需要保存它的状态
g)gcc认为用32字节来保存所有的局部变量和剩余无法存放在寄存器中的函数的参数就足够了(32字节对应4个栈单元)
h)上面g的好处是为了尽量减少栈指针(rsp)的移动次数,简化编译器用相对于栈指针的偏移量产生对栈元素的引用的任务
i)在函数开始没有push ebp(32位下为push ebp+mov ebp,esp)了,变成了subq $32,%rsp
j)函数最多可以访问超过当前栈指针(rsp)128个字节的栈上存储空间(address<rsp的内存地址空间)
k)x86-64 ABI将j中的这个区域称为红色地带,必须保持当rsp移动时,红色地带可读可写
l)阅读64位反汇编代码可参考如下链接
17.为什么IA32中ebp+0的下一个(高地址)栈单元的地址是ebp+4而不是ebp+0x20? [(x86-64)中ebp+8的下一个栈单元的地址是ebp+16]
IA32中每个栈单元是32位(4个字节大小),而计算机的最小存储单元是字节,也即eg,如果0x10000000中开始的内存内容为abcd,
那么0x10000001中存放的内容为b,也即1个内存地址差对应8位(1字节)的内存容量,如下图od截图中左下角的数据窗口中内存
地址与内容数据的对应关系.